If mechanistic modeling is to become a focal point in the project lifecycle, you have to address the question of where the models will come from. In this context, by 'model' we mean i) the set of equations to be solved, ii) in executable form, with iii) initial values, iv) fitted parameter values where needed and v) experimental data to assess model accuracy.
Q: Who can create these models and when does it make sense for them to do so?
A: For tangible benefits the creators and users should be the same practitioners / project teams that own and run the development projects. Not some specialists in an ivory tower that are focused only on modeling. Model development should occur before and during experimentation. Modeling should not be a 'post-processing' activity that occurs too late to add value or when the time window for data collection has passed.
In Dynochem 5 and Reaction Lab, we have streamlined the process in i) to v) so that this vision is achievable. We include further notes on the individual steps below.
Item (i) may be clear and simple for certain common unit operations like heating/ cooling and perhaps filtration; for many other operations, identifying which equations to solve may be iterative and challenging. For models of fairly low complexity, like distillation, while the equation set may be obvious it is unwieldy to write down for multi-component systems including the energy balance. For models of chemical reactions, the set of elementary reactions will not become clear until the full cycle i)-v) has been repeated more than once by knowledgable process chemists.
Unlike some other tools, we do not force users to populate 'matrices' just to define reactions and reaction orders (!)
Item ii) is an obstacle for practitioners who only have access to spreadsheets, or specialized computing/coding environments. These force the user to develop or select a specific solution method and run risks of significant numerical integration inaccuracies. Even then, simulations will lack interactivity and parameter estimations will require scripting or complex code. Some 'high-end' engineering software tools present similar challenges, lacking comprehensive model libraries and forcing users to write custom models, delve into solution algorithms and confront challenges such as 'convergence' that feel highly tangential to project goals.
Item iii) should be easy for practitioners and in practice it can be so, if the software supports flexible units conversion (in and out of SI units) and contains supporting tools to provide initial estimates of physical properties and equipment characteristics.
Item iv) requires the model to be run many times and compared with experimental results. Specialized algorithms are needed to minimize the gap between model predictions and experimental data. When multiple parameters must be fitted to multiple responses in multiple experiments, this gets close to impossible in a spreadsheet model and general-purpose mathematical software environments.
Item v) is mainly the province of the experimenter and once each experiment has been completed, requires an easy mechanism for aggregating the data, with flexible units handling (including HPLC Area, Area%) being a major help.
And so to answer the question in the title of this post: You guessed it! We expect the majority of chemical reaction and unit operation models in Pharma to continue to be developed using our tools in preference to home-made or overly complex environments. As the volume of modeling activity grows with Industry 4.0 and related developments, we already see this trend becoming more pronounced, with many practitioners needing to use the same model over a project lifecycle, requiring speed and ease of use as well as accuracy and rigour.
Q: Who can create these models and when does it make sense for them to do so?
A: For tangible benefits the creators and users should be the same practitioners / project teams that own and run the development projects. Not some specialists in an ivory tower that are focused only on modeling. Model development should occur before and during experimentation. Modeling should not be a 'post-processing' activity that occurs too late to add value or when the time window for data collection has passed.
In Dynochem 5 and Reaction Lab, we have streamlined the process in i) to v) so that this vision is achievable. We include further notes on the individual steps below.
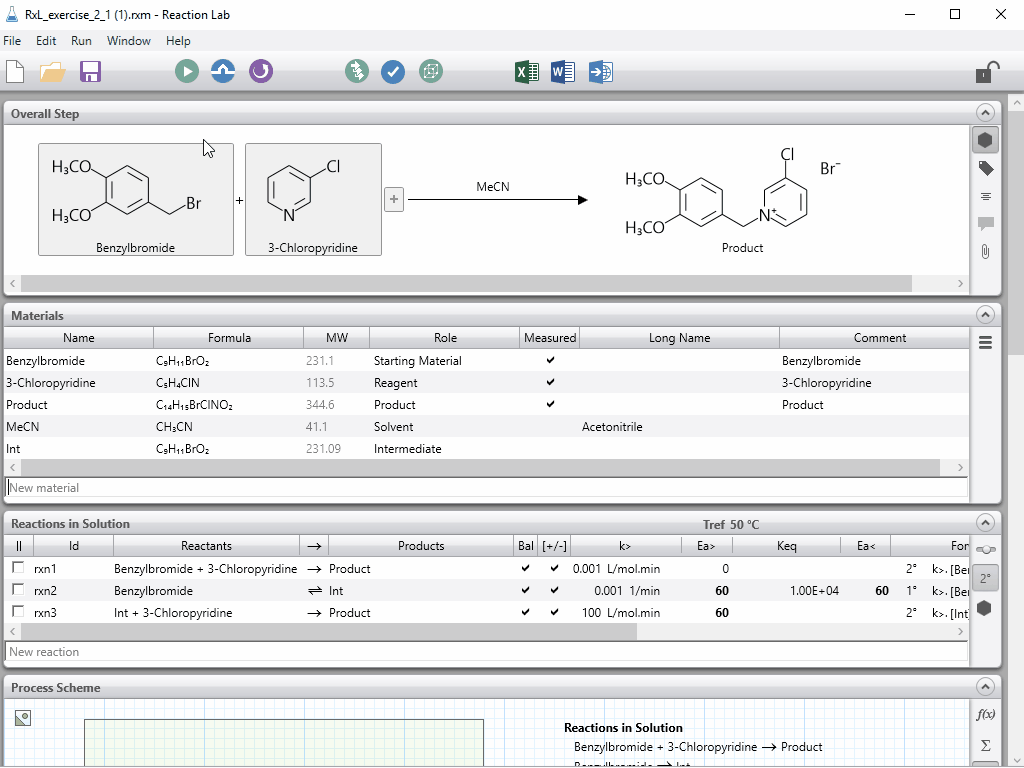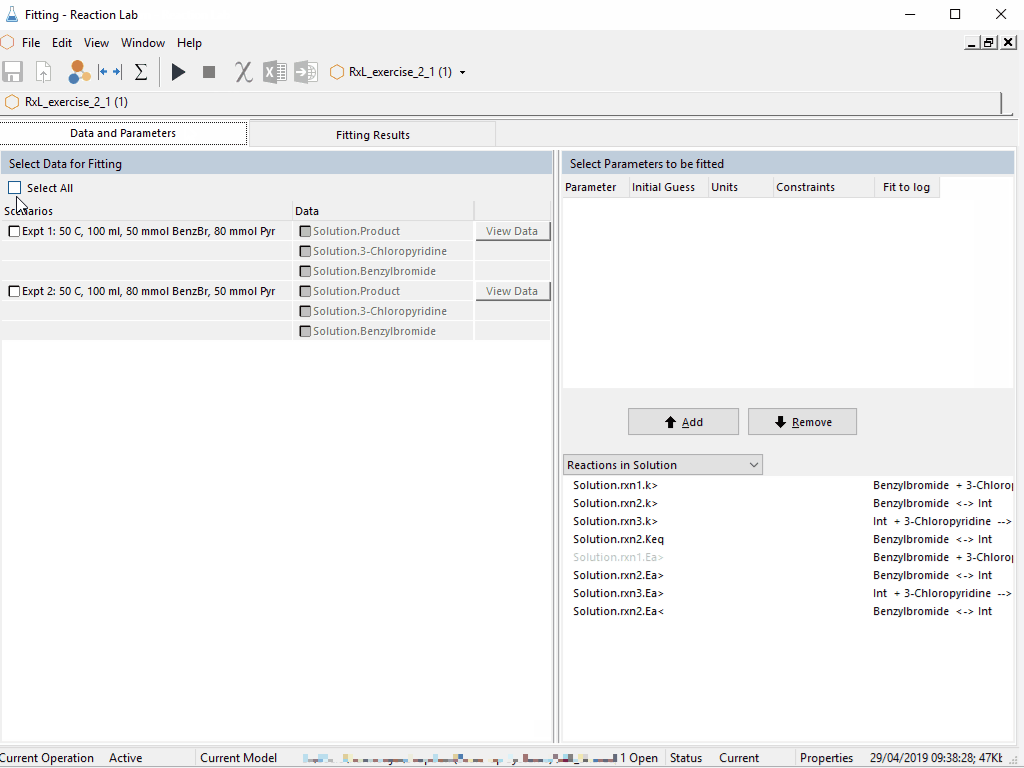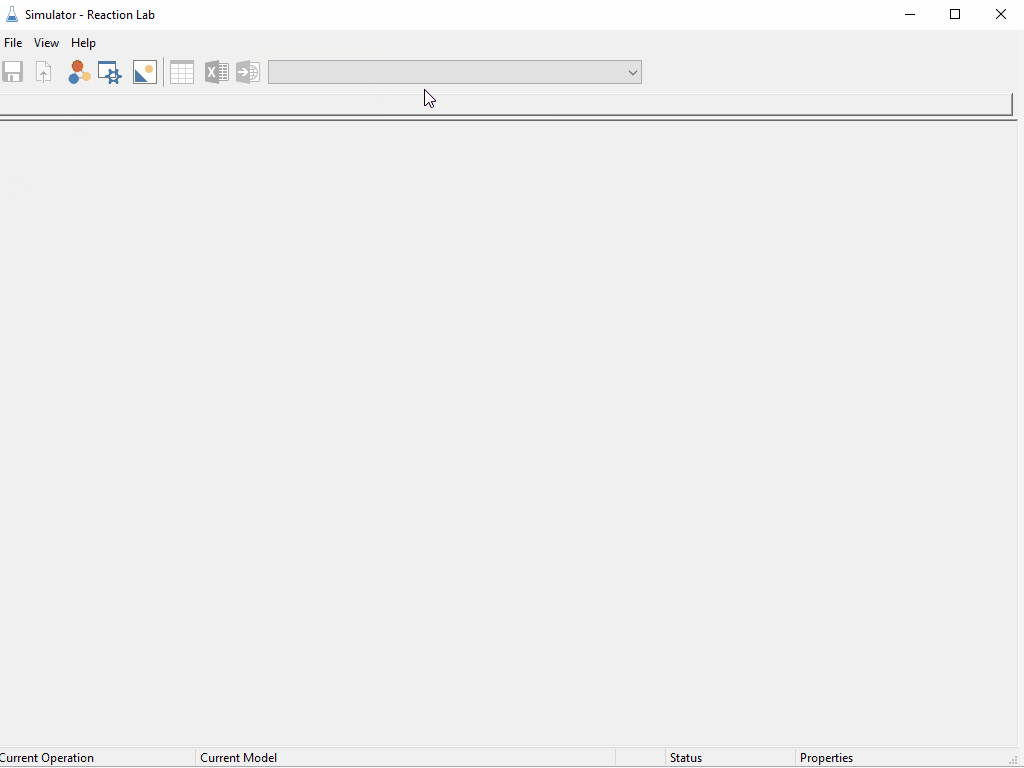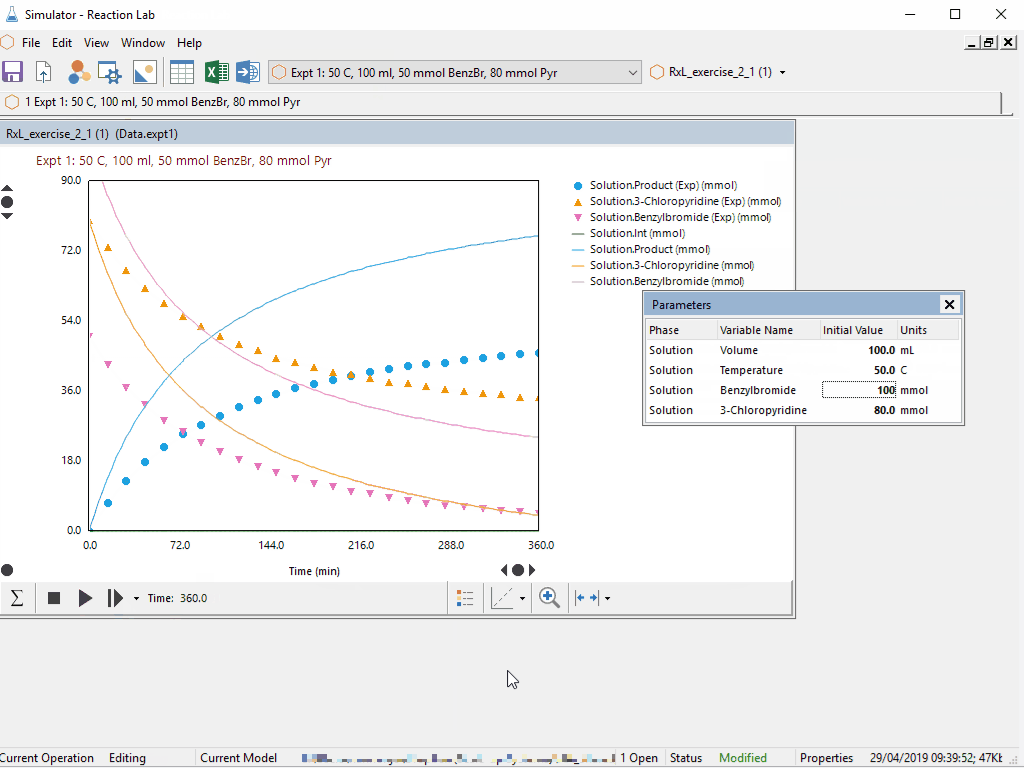 |
| Steps i) to v) can be accomplished in a snap for chemical reactions using Reaction Lab. The resulting model can be leveraged over and over during the project lifecycle. |
Unlike some other tools, we do not force users to populate 'matrices' just to define reactions and reaction orders (!)
Item ii) is an obstacle for practitioners who only have access to spreadsheets, or specialized computing/coding environments. These force the user to develop or select a specific solution method and run risks of significant numerical integration inaccuracies. Even then, simulations will lack interactivity and parameter estimations will require scripting or complex code. Some 'high-end' engineering software tools present similar challenges, lacking comprehensive model libraries and forcing users to write custom models, delve into solution algorithms and confront challenges such as 'convergence' that feel highly tangential to project goals.
Item iii) should be easy for practitioners and in practice it can be so, if the software supports flexible units conversion (in and out of SI units) and contains supporting tools to provide initial estimates of physical properties and equipment characteristics.
Item iv) requires the model to be run many times and compared with experimental results. Specialized algorithms are needed to minimize the gap between model predictions and experimental data. When multiple parameters must be fitted to multiple responses in multiple experiments, this gets close to impossible in a spreadsheet model and general-purpose mathematical software environments.
Item v) is mainly the province of the experimenter and once each experiment has been completed, requires an easy mechanism for aggregating the data, with flexible units handling (including HPLC Area, Area%) being a major help.
And so to answer the question in the title of this post: You guessed it! We expect the majority of chemical reaction and unit operation models in Pharma to continue to be developed using our tools in preference to home-made or overly complex environments. As the volume of modeling activity grows with Industry 4.0 and related developments, we already see this trend becoming more pronounced, with many practitioners needing to use the same model over a project lifecycle, requiring speed and ease of use as well as accuracy and rigour.
No comments:
Post a Comment