We have been using a 'mixing' variable to represent the effects of non-pharmaceutical measures / interventions on the rate of exposure to COVID-19:
This parameter reflects the relative contact rate between infectious and susceptible and also the probability of transmission during contact. Baseline mixing = 1.0, i.e. what we did before the outbreak. To date, this variable has been reduced by lockdowns and closures (reducing our contact rate) and physical distancing, handwashing, mask wearing (reducing the probability of transmission). When we are exiting lockdowns, our contact rate will return gradually towards the baseline but if we maintain or improve current standards of physical distancing, handwashing and mask wearing, the mixing term in the model will not return to 1.0. This will be very important in preventing large subsequent waves of infection.
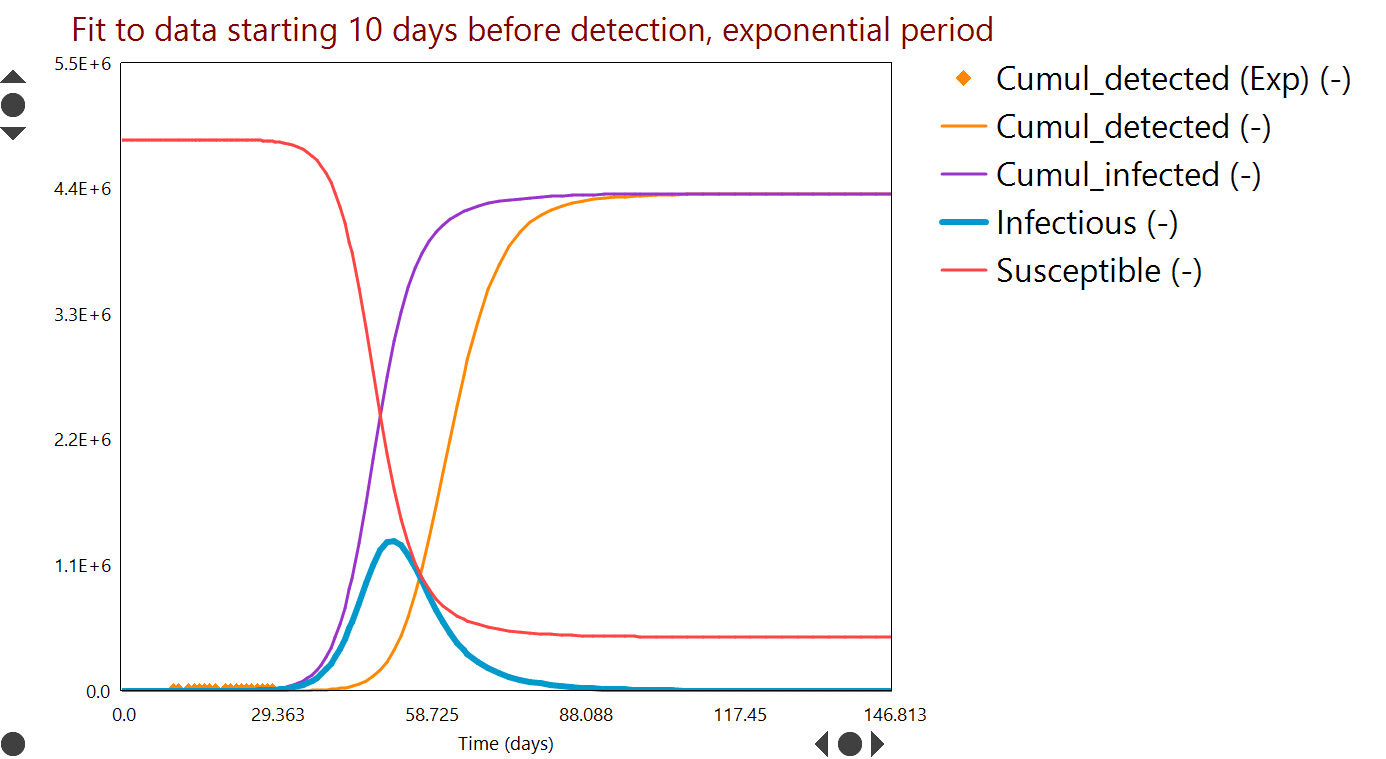
As noted in last week's update, Ireland, Italy and the United States have reduced infection rates during lockdown by at least two thirds. Some of the benefit came from reduced contact and some from reduced probability of infection; at this time it is difficult to split the effects accurately; however it is likely that the reduced probability accounts for a significant portion of the effect.
In addition to including the latest data in our models this week, we have updated the lines (on the process worksheet) that allow simulation of the effect of relaxing the measures that reduced contact. Most countries will relax measures over a period of several months starting soon, while maintaining focus on hygiene and distancing and in many cases encouraging the wearing of masks. Our models currently simulate a linear relaxation of measures, though in practice these will occur in 'steps' or 'phases'. We also include the option of a return to current lockdown for a short period at any time. Users can define the ultimate 'relaxed' value of the mixing variable and to begin with we have set this to 45% of baseline. We chose this value in the hope that measures affecting probability of transmission will be maintained and that they are highly effective; and that as many people as possible will be able to continue to work from home.
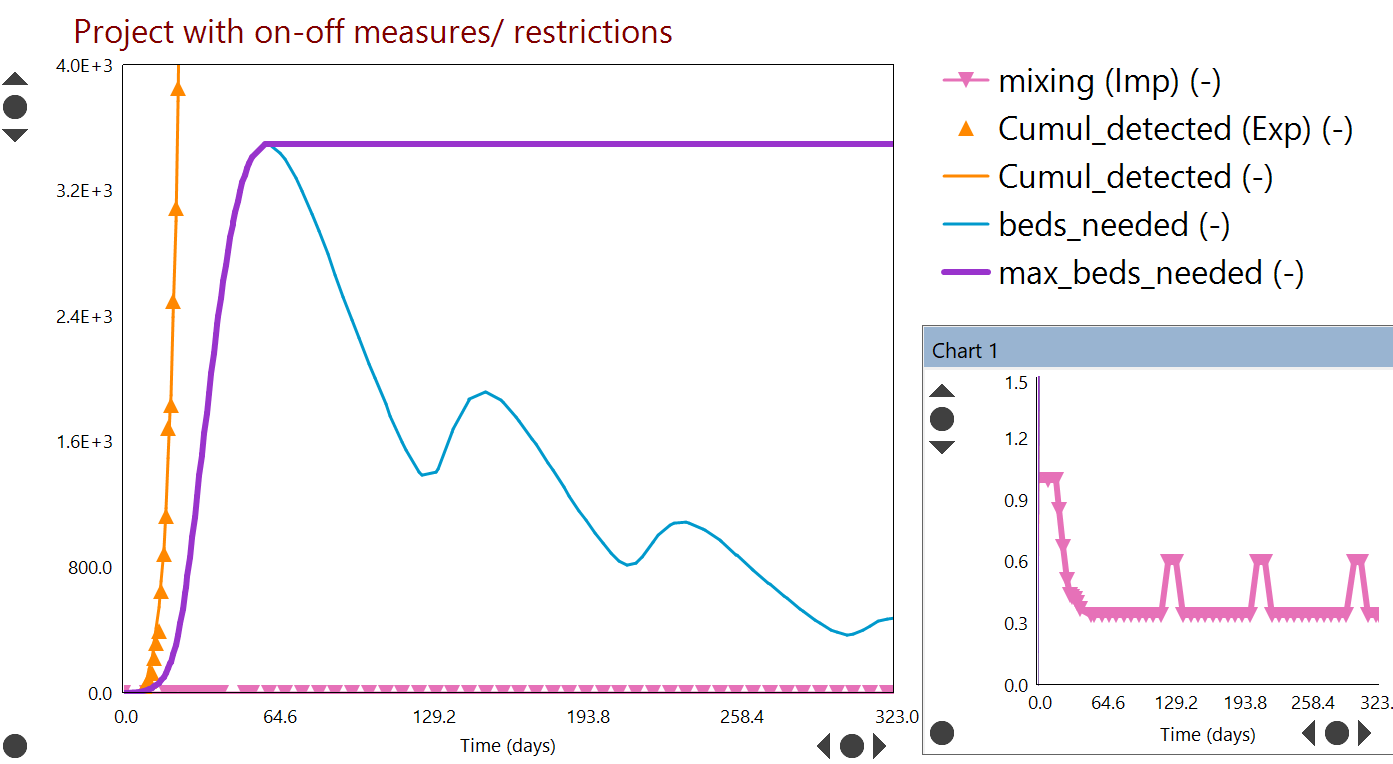
Example projections are shown below for the US as a whole, with linear relaxation of lockdown measures to mixing = 45% of baseline (inset) over a period of months. Even with these potentially optimistic parameter values, a very large second wave of infections could occur before the end of the year. It seems likely therefore that in order to control the level of infection, it will be necessary to have periods during which we return to current levels of lockdown.
 |
| The rate of change of the number of people currently exposed depends on i) the relative contact rate between infectious and susceptible and ii) the probability of transmission during contact; these are reflected together in the 'mixing' term |
As noted in last week's update, Ireland, Italy and the United States have reduced infection rates during lockdown by at least two thirds. Some of the benefit came from reduced contact and some from reduced probability of infection; at this time it is difficult to split the effects accurately; however it is likely that the reduced probability accounts for a significant portion of the effect.
In addition to including the latest data in our models this week, we have updated the lines (on the process worksheet) that allow simulation of the effect of relaxing the measures that reduced contact. Most countries will relax measures over a period of several months starting soon, while maintaining focus on hygiene and distancing and in many cases encouraging the wearing of masks. Our models currently simulate a linear relaxation of measures, though in practice these will occur in 'steps' or 'phases'. We also include the option of a return to current lockdown for a short period at any time. Users can define the ultimate 'relaxed' value of the mixing variable and to begin with we have set this to 45% of baseline. We chose this value in the hope that measures affecting probability of transmission will be maintained and that they are highly effective; and that as many people as possible will be able to continue to work from home.
Example projections are shown below for the US as a whole, with linear relaxation of lockdown measures to mixing = 45% of baseline (inset) over a period of months. Even with these potentially optimistic parameter values, a very large second wave of infections could occur before the end of the year. It seems likely therefore that in order to control the level of infection, it will be necessary to have periods during which we return to current levels of lockdown.
 |
| Model fit to known cases and reported deaths to date for the US (symbols and curves of the same colour). Then projecting to end 2020 with a linear relaxation of restrictions on movement [inset], to a new stable mixing level of 45%. |