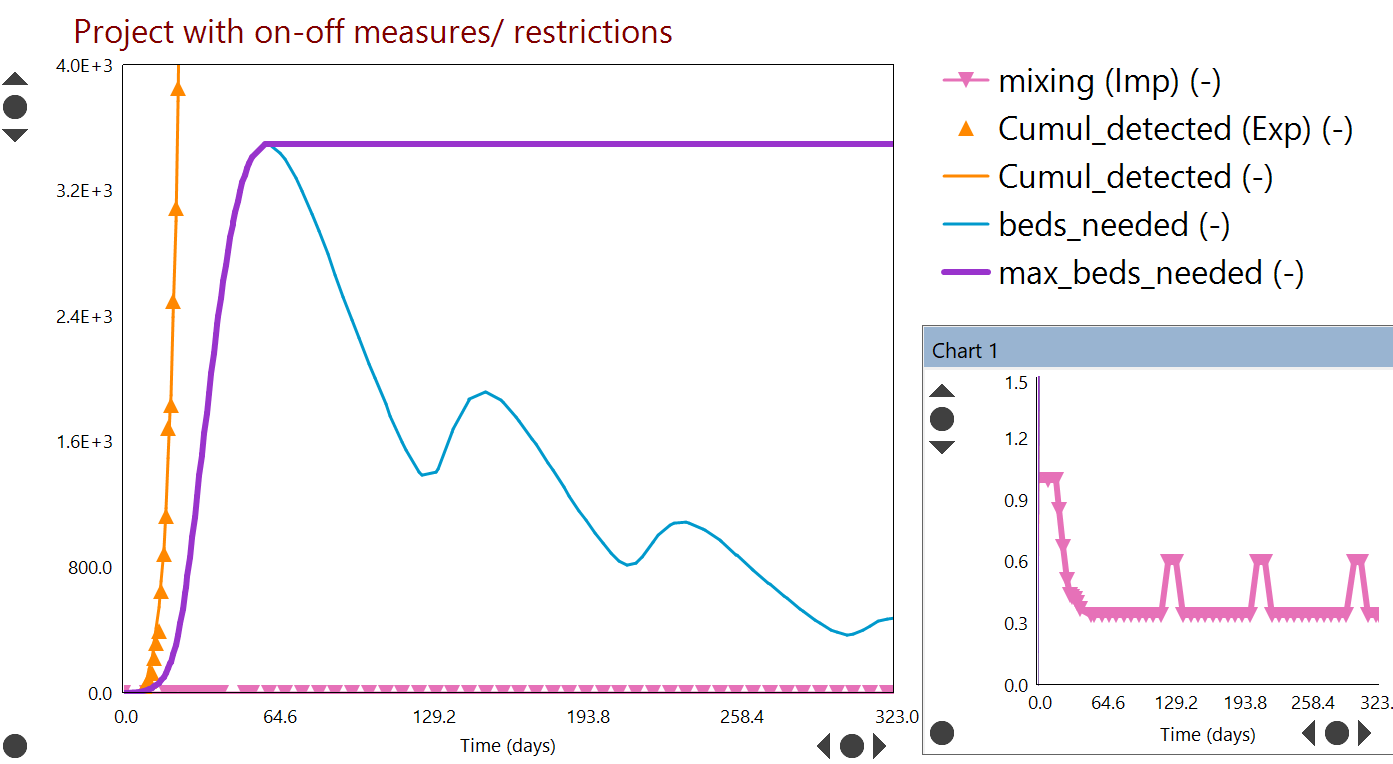
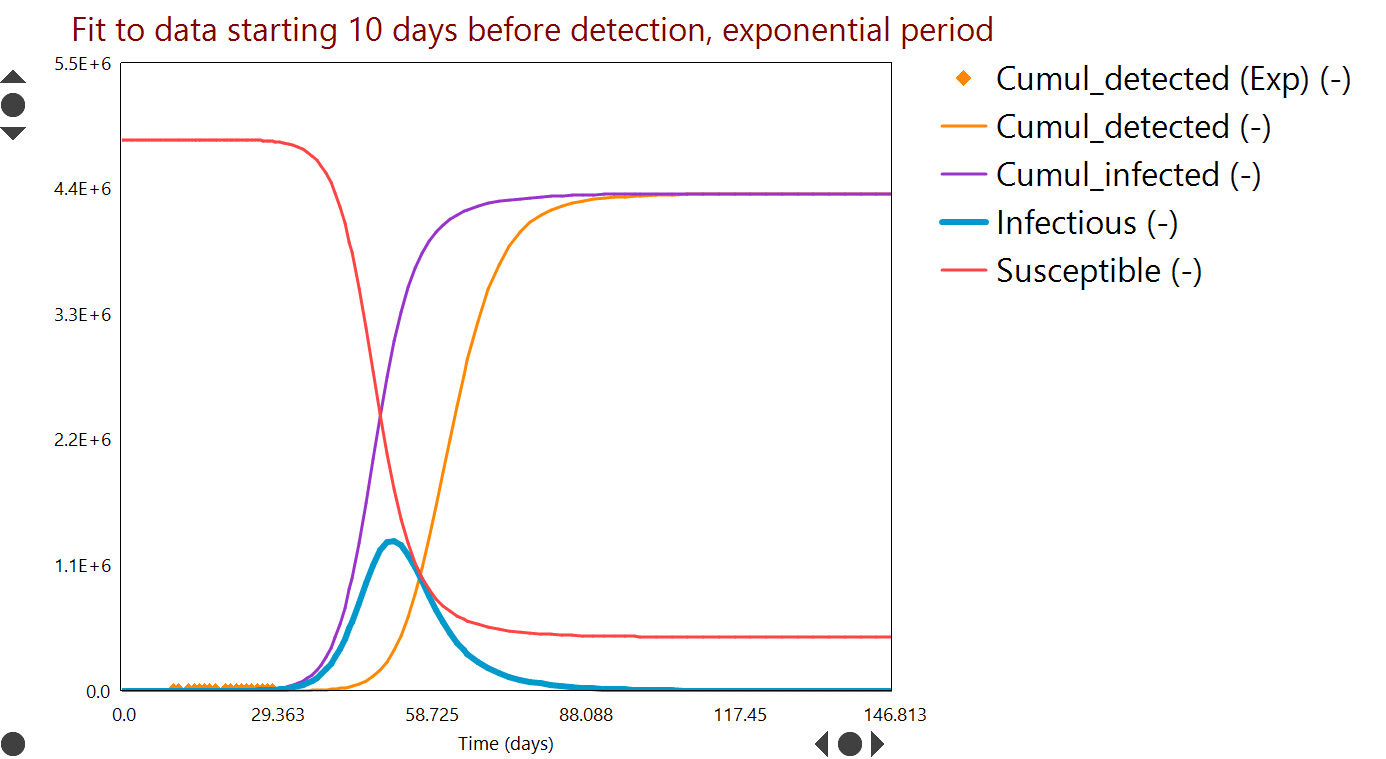
Many of our posts on the blog this year have been about the pandemic, predicting its course and interpreting reported data for cases and deaths.
We have seen that population level Dynochem models have been sufficiently accurate to describe the data for each country and quantify the potential future impact of the outbreak as well as the effectiveness of non-pharmaceutical measures, such as lockdowns and the wearing of masks.
Our models for the outbreak will remain available to the user community on our COVID site. We do not plan to further develop or update the models for the foreseeable future.
New content on the blog will return to our core focus, positively impacting the development of medicines by our customers, the global pharmaceutical industry.
We are proud to serve the pharmaceutical industry, supporting daily core business activities at more than 100 organizations that develop or make medicines. The industry response to COVID-19 has been inspiring and no less than we expected, having worked with some of these companies for two decades.
All of our normal activities including software development, user support and training have continued in a fully operational state and we have seen increased activity from customers both using and learning the tools. Of course we are delivering all events on-line for now. Public training events are half price during the outbreak and we have been offering training licenses to customers delivering their own internal curriculum.
We have ramped up our own support for unit operations likely to be involved in manufacturing vaccines and treatments, including bioreactors and lyophilization.
We would be delighted to hear from members of the community anytime if you have ideas or suggestions as to how we could do more, by email to support@scale-up.com.
 |
| Our Reaction Lab software helps chemists develop kinetic models, maximize yield and minimize impurities. |